

语音识别芯片技术的原理
语音识别技术的原理
定义:语音识别技术(ASR Automatic Speech Recognition),让智能设备听懂人类的语音。语音识别的工作流程,可以分为三大部分:前端语音处理、模型训练、后端识别处理
1、前端处理
前端处理,即将声音的模拟信号,转换成机器能处理的数字信号,并对信号进行优化。语音识别的硬件链路通常是:MIC 麦克风—>ADC/PDM(模数转化)——>Codec/DSP/NPU(信号优化和处理)。其中麦克风/ADC/PDM为前段处理部分,DSP/NPU的部分(例如降噪算法)也属于前段处理。
MIC 麦克风 采集外部声音的硬件,关键参数是灵敏度dB和信噪比SNR。 按信号输出分:模拟麦和数字麦,数字麦是在模拟麦的基础上内置ADC,直接对外输出数字信号。
按产品形态分:驻极体ECM和硅麦MEMS,前者工艺成熟成本低,后者体积小,常见于手机应用。
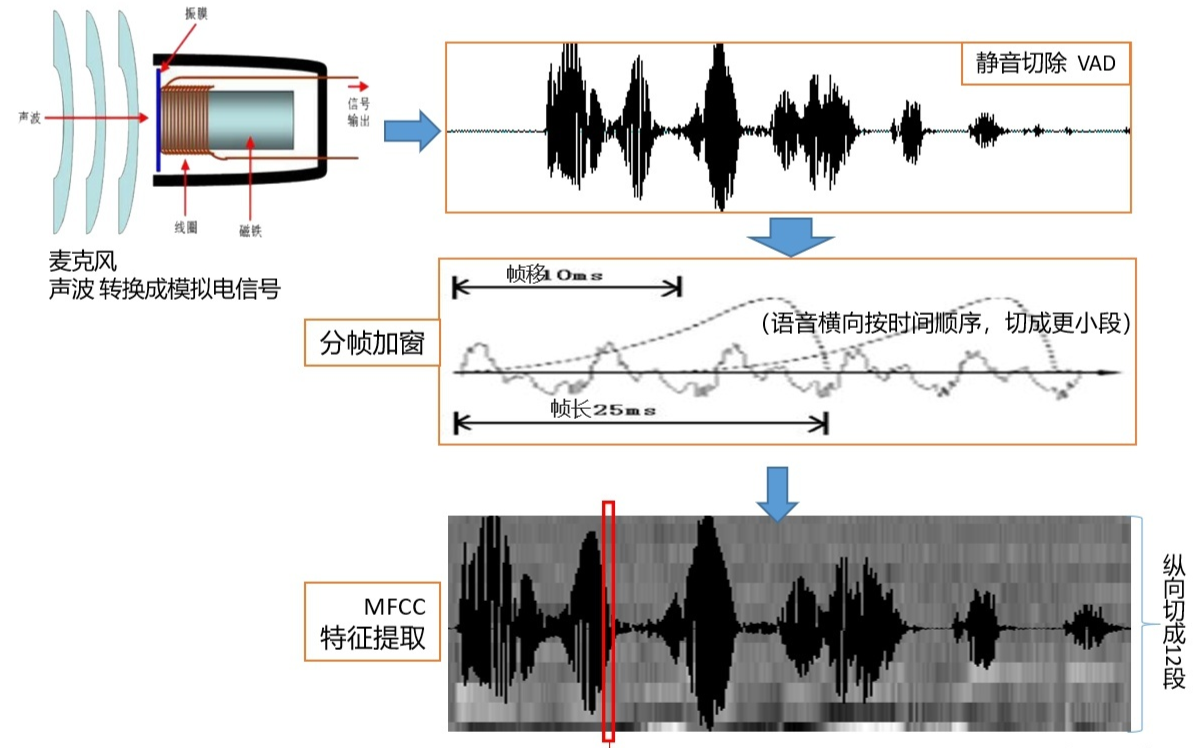
前端处理的原理简化描述:
音频采集:通过麦克风,将声波转换为模拟电信号,再通过ADC转换为数字信号
预处理:静音切除 VAD、分侦加窗、降噪(主动降噪ANC)、预加重等
特征提取:图中选的是主流的MFCC,其他还有LPCC,PLP等,选取后续可以匹配的特征点
- 模型训练
模型可以简单理解为“字典”,机器可以查字典,去比对输入的信息,找出正确答案近几年的模型训练发展,开始纳入语言模型,让机器能翻译出人类语言,进而达到更准确的识别效果。
声学模型训练:
声学模型是识别系统的底层模型,是语音识别系统中关键的部分,算法主要集中优化该部分。
声学模型是通过大量的语音收集,并根据特定的算法规则获得特征值,用于后面的识别比对。
语言模型训练:
语言模型是用来计算一个句子出现概率的概率模型,是语音识别中的”字典”
它需要综合三个层次的知识:字典,语法,句法,让机器能更好理解人类的自然语言。
3、后端识别处理 (语音解码)
应用中实时将人声采集进来,跟“声学模型”和“语言模型”匹配比较,并输出正确的识别结果该步骤跟模型建立有深度关联,有时将”模型建立”归类到后端识别处理中,与前端处理对应识别准确率和响应速度,综合取决于算法优化,硬件主频,以及前端信号的降噪能力(分离人声)。
按照市场主流的观点,我们将语音识别区分为在线和离线:
在线语音识别,即大词汇量连续语音识别系统 ,拥有智能交互的特点
典型应用:智能音箱、智能手机助手、在线翻译、智能客服等
离线语音识别,即小词汇量、低成本的语音识别系统,应用场景相对单一
典型应用:智能家电、语音遥控器、智能玩具、车载声控、智能家居等
离线和在线最大的区别在于,在线语音识别需要联网,实际的语音识别过程在云端或服务器(高性能处理器和大容量数据存储),需确保网络连接稳定和通畅。离线则无需联网和任何其他外部设备的支持,上电即可使用,语音识别工作发生在本地设备(低成本MCU/NPU/DSP和极小存储容量)。离线的存在,可以简单视为在线语音技术的简化版,将场景单一化减少需要识别的对象,实现硬件成本最低化,更符合广大消费者的价格需求。
